1. Introduction
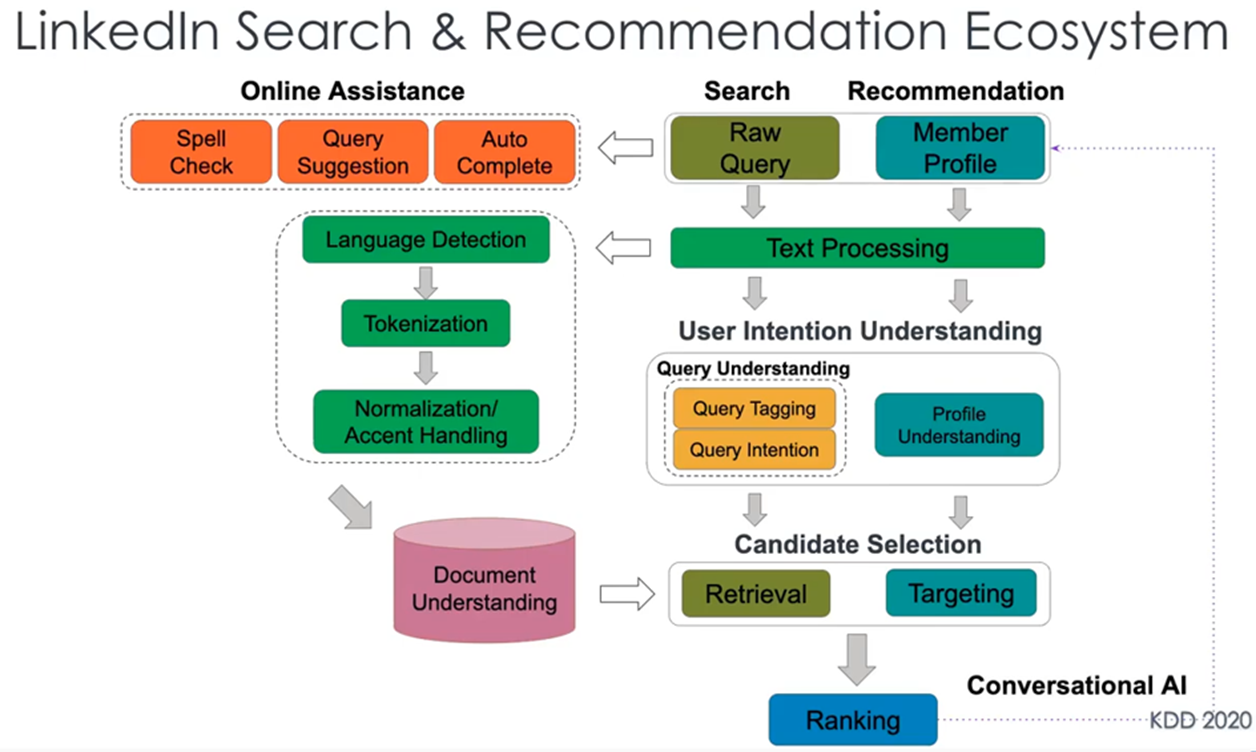
LinkedIn의 Search & Recommendation Ecosystem에 들어가는 아키텍쳐는 아래와 같은 모습으로서
엄청나게 많은 엔진들이 하루에 수천만번 검색이 이루어지는 대형 포털사이트에서 돌아간다. 최근의 BERT같은 자연어 모델은 분명 NLP에서 뛰어난 성과를 보이고 있지만, 검색 시스템에 직접 적용하기에는 BERT 모델의 높은 계산 비용으로 인해 매우 큰 부담이다.
그래서 링크드인에서는 직접 다양한 사례를 연구해서 BERT를 기반으로 모델을 구축하는 검색 시스템의 Ranking 시스템 프레임워크 DeText를 소개하고, 또한 인기 있는 NLP 모델에 새로운 기능을 부여하는 방법을 설명한다.
DeText를 사용하면 사용자는 작업 유형에 따라 NLP 모델을 교환하고 모델을 활용하여 이전보다 더 나은 검색 및 추천 시스템을 만들 수 있고, 검색/추천 및 쿼리 의도 분류, 쿼리 자동 완성 등 LinkedIn의 다양한 어플리케이션에 활용되는 것을 보며 코드를 오픈하여 연구 및 산업 커뮤니티가 프레임워크를 채택하는데 도움이 되고 활성화되기를 희망하며 작성한 오픈소스 논문이다.
2. Detext Architecture
아래는 DeText의 Architecture 그림이며 각 Layer별 설명을 추가한다.
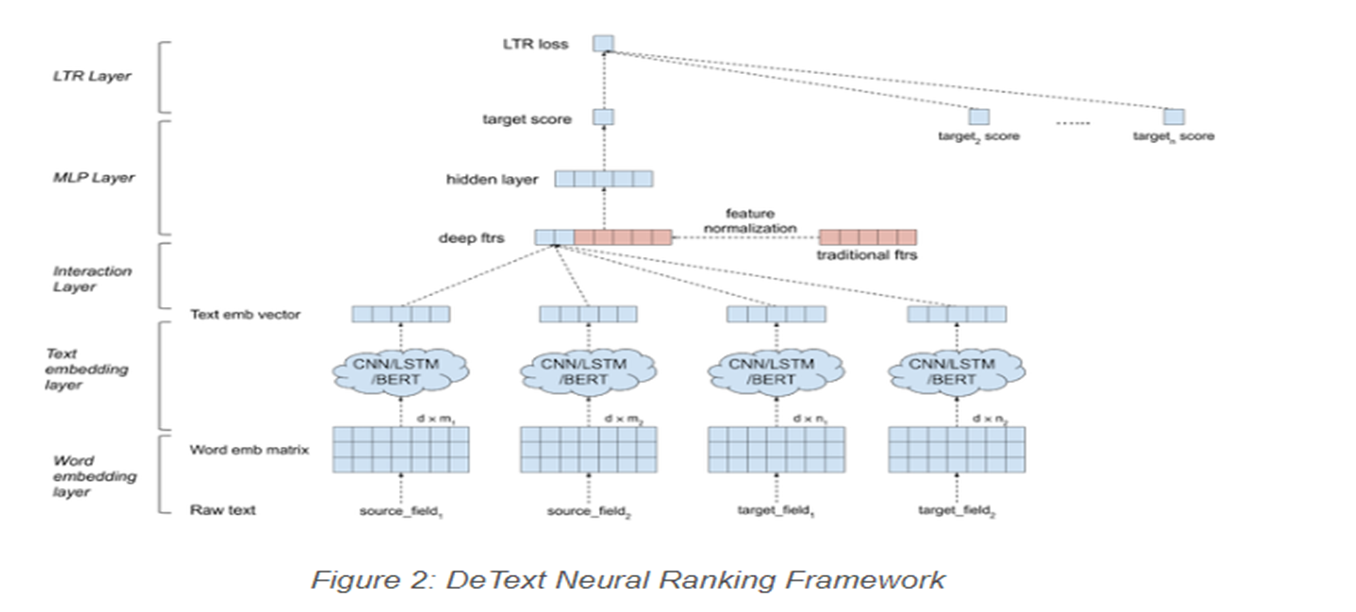
Input text data: The input text data are generalized as source and target texts. The source could be queries (in search systems) or user profiles (in recommender systems). The target could be the documents. Both source and target could have multiple fields.
Word embedding layer: The sequence of words are transformed into an embedding matrix.
Text embedding layer: DeText provides CNN/LSTM/BERT to extract text embedding. CNN/LSTM are provided as a lightweight solution with small latency. In other cases where complicated semantic meaning extraction is needed, BERT can be used.
Interaction layer: Multiple interaction methods are available to compute deep features from the source and the target embeddings: Cosine Similarity, Hadamard Product, Concatenation, etc.
Traditional feature processing: Feature normalization and element-wise rescaling is applied to the hand-crafted traditional features. By doing this, the deep learning models are at least as good as the shallow models.
MLP layer: The deep features from the interaction layer are concatenated with the traditional features. These features are fed into a Multilayer Perceptron (MLP) layer to compute the final target score. The hidden layer in MLP is able to extract the non-linear combination of deep features and traditional features.
LTR layer: The last layer is the learning-to-rank layer that takes multiple target scores as input. DeText provides the flexibility of choosing pointwise, pairwise or listwise LTR, as well as Lambda rank. In applications focusing on relative ranking, pairwise and listwise LTR can be used. When modeling the click probability is important, pointwise LTR can be used.
3. Detext Online Deployment Strategy
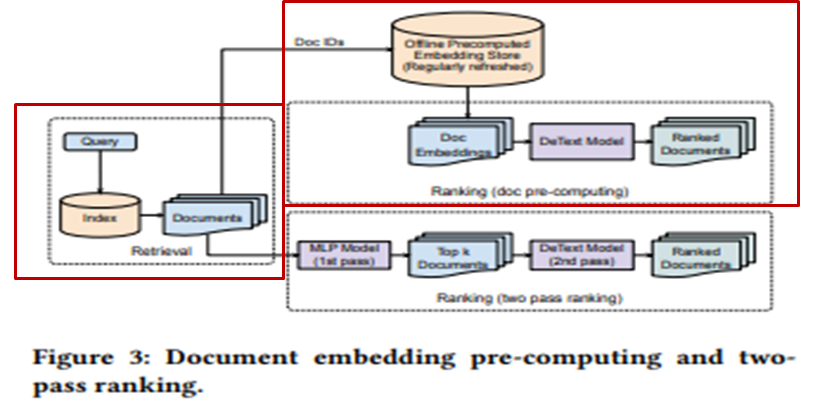
본 논문에서는 DeText를 활용하기 위해 2가지 방법을 제시한다.
1. Tanditional Feature만을 이용하여 MLP를 이용하여 TOP K개의 문서를 추출하고 DeText(CNN) 모델을 통함.
CNN을 사용함에 있어, Feature 수를 바꿔가며 테스트 해봤으나 크게 달라지지 않아서 필터는 64개로 정함.
몇만개의 문서중에 MLP를 통해 TOP K개의 문서만을 추출하여 DeText(CNN)을 사용하기에 속도가 빠름
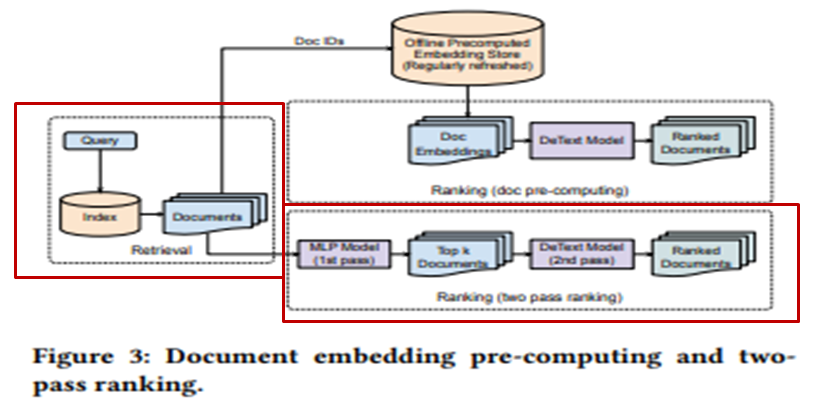
2. 링크드인 데이터(서치, 멤버 프로필 등의 데이터)를 통해 만든 리버트(LiBERT)
기존의 버트보다 리버트가 파라미터 개수가 3분에 1 감소, 레이턴시도 30% 감소, 레이어는 12레이어에서 6레이어로 감소
오프라인으로 임베딩을 먼저 계산하여 키 밸류 쌍으로 스토어에 먼저 저장 (키는 Document ID, 밸류는 임베딩 벡터)
임베딩 스토어에서 미리 계산된 임베딩 벡터를 통해 DeText(LiBERT)를 사용하기에 속도가 괜찮음
4. Experiment & Result
5. Conclusions
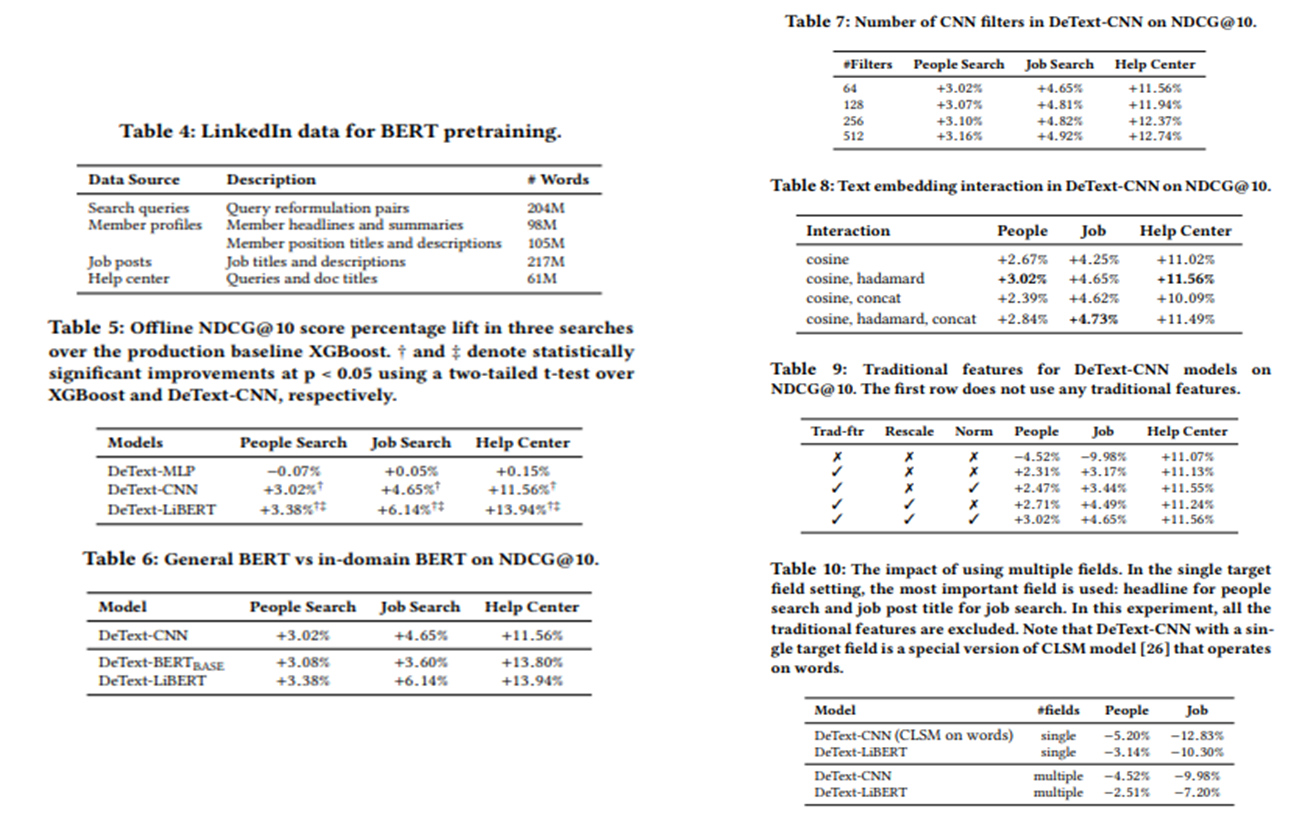
저자는 다양한 LinkedIn 어플리케이션에 DeText를 적용했고, 검색 랭킹에서 사람 검색, 구직 검색 및 헬프 센터 검색 등에서 비즈니스 메트릭이 상승하는 것을 관찰했다. 또한 쿼리 의도 분류 작업과 쿼리 자동 완성과 같은 시퀀스 완성 작업에서 상당한 개선이 이루어졌다고 말한다. 검색 시스템 관련해서는 논문을 처음 접해보긴 했으나 상당히 흥미 있는 주제였고, 또한 검색시스템 뿐만 아니라 다양한 분야(온라인으로 실시간 서빙이 필요한)에서도 이러한 방법을 이용하여 큰 언어 모델인 BERT나 여러 다른 모델들을 사용하는 방법에 대해 생각해볼 수 있는 논문이다.
https://arxiv.org/abs/2008.02460
DeText: A Deep Text Ranking Framework with BERT
Ranking is the most important component in a search system. Mostsearch systems deal with large amounts of natural language data,hence an effective ranking system requires a deep understandingof text semantics. Recently, deep learning based natural language
arxiv.org




댓글